|
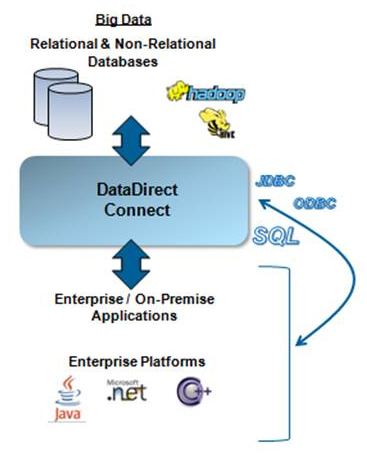
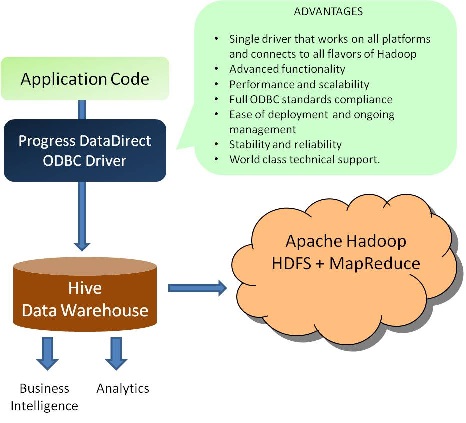
DataDirect driver for Apache Hive는 ODBC규범을 완벽히 준수하면서 multiple Hadoop distributions 환경에 특화된 유일한 ODBC driver 입니다. Apache Hive ODBC driver 로 DB 연결과 증가하는 대량 데이터의 import/export에 최상의 성능을 제공합니다.
DataDirect는 Hadoop JDBC driver로 Hadoop DB에서 데이터를 추출하여, DataDirect JDBC Driver로 Oracle, DB2, SQL Server, Sybase, 그리고 타 relational DB로 bulk load 할 수 있습니다.
아래와 같이 대량의 데이터를 처리할 때 유용하게 사용할 수 있습니다.
|
Data Warehousing |
Bulk Load delivers the best performance for loading bulk data into an Oracle, DB2, Sybase, or SQL Server-based data warehouse – while avoiding data latency issues |
|
Data Migration |
Bulk Load is ideal for extract and load data migration operations – whether simple or more complex. |
|
Data Replication |
Rather than use FTP or pushing files around a network, Bulk Load functionality can allow for quickly loading data into relational database tables. This approach is faster and provides the benefit of storing the data as a relational database table easily accessed by reporting or Business Intelligence applications. |
|
Disaster Recovery |
Bulk Load can ensure that the data is quickly and easily replicated into disaster recovery databases. |
|
Cloud Data Publication |
Bulk Load allows developers to quickly and easily build a simple program that publishes Big Data into the cloud in a way which uses resources efficiently. |
|
|
잘 튜닝된 프로그램의 경우 처리속도의 90%이상은 DB Driver가 data를 액세스하는데 소요됩니다. 그러므로 Big data를 처리해야 할 경우 DB Driver의 역할은 더욱 커지게 됩니다. 기업은 Big Data를 기존의 data인프라에 완벽하게 융합을 시켜야 합니다.
DataDirect ODBC, JDBC, ADO.NET driver가 이를 가능하게 해줍니다.
-
Guarantee the availability of any size data from any source
-
-
Manage 'single-driver' connectivity to a wide array of enterprise databases and platforms
-
Deliver the best possible bulk load performance, scalability and reliability
-
Deploy with no application code changes or database vendor tools
-
Reduce the time, cost and risk of making new data sets available to enterprise users |
|
 High-performance and throughput with support for Hive2 and concurrent connections High-performance and throughput with support for Hive2 and concurrent connections
Improved authentication for increased data security
Cloudera CDH 4.5 certification plus Cloudera Hive2 support
Support for Hive Kerberos
In addition to Cloudera, support for Apache, MapR, and Amazon EMR Hadoop distributions
Windows, RedHat, Solaris, SUSE, AIX, and HP-UX platform support
SELECT, INSERT [OVERWRITE] SELECT, LOAD, and CREATE/DROP Hive grammar support
Full driver metadata
Support for parameter arrays, processing the arrays as a series of executions, one execution for each row in the array
Support for standard SQL functionality, including Create Index, Create Table, Create View, Drop Index, Drop Table, Drop View
Support for a wide range of data types: Int, TinyInt, SmallInt, BigInt, String, Double, Binary, Boolean, Float, and Timestamp
|